
Course 1
监督学习:输入特征x,输出目标y。对数据集进行预测,分为回归和分类
无监督学习:输入特征x,没有目标y,对数据集进行聚类预测,异常检测,降维
线性回归
$$
y^i = wx^i+b
$$
定义损失函数(成本函数),需要最小化损失函数
$$
J(w,b) = \frac{1}{2m} \sum_{i=1}^{m} {(y^i-\hat{y})}^2
$$
其中$y^i$为真实输出,$\hat{y}$为预测输出
- 为了不让数据集变大而损失也变大,故采用平均平方误差而不是总平方误差
- 1/2是为了方便求导计算
loss针对一个训练样本,cost是所有训练样本的均值
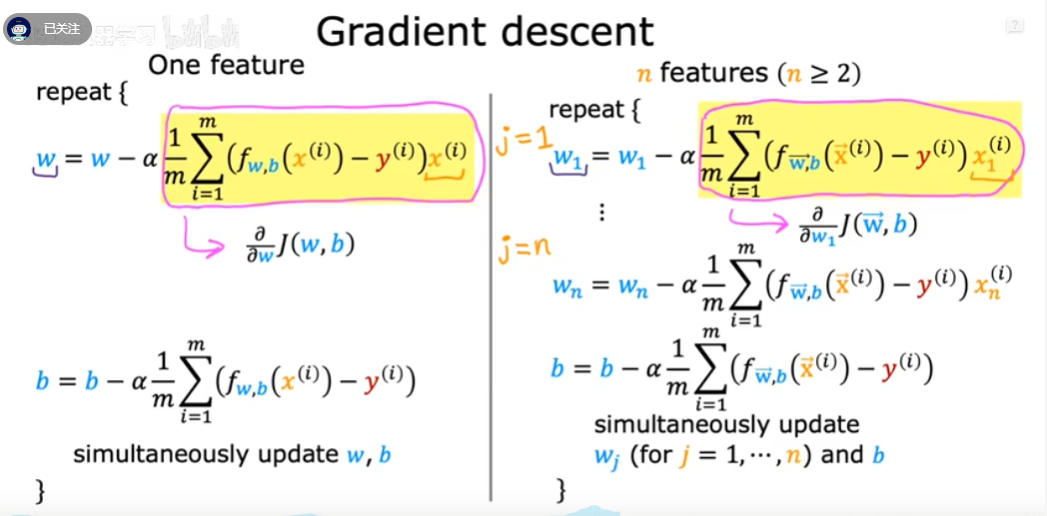
梯度下降
需要最小会损失函数,需要使用梯度下降算法
定义学习率learning_rate为$\alpha$,一般$\alpha \subseteq [0,1]$
$w = w- \alpha \frac{\partial{J(w,b)}}{\partial{w}}$
$b = b- \alpha \frac{\partial{J(w,b)}}{\partial{b}}$
- 梯度下降时建议同步梯度下降,如下图

如果$\alpha$太小,可以得到答案,但是时间过长
如果$\alpha$太大,大交叉无法收敛,甚至发散
当参数值每次更新时,$J(w,b)$变小,导数项(斜率)也会变小,对于固定学习率$\alpha$,步长也会变小,从而达到局部最优解
对导数项分别求导
$\frac{\partial{J(w,b)}}{\partial{w}} = \frac{1}{m} \sum_{i=1}^{m} (f(x^i)-y^i)x^i$
$\frac{\partial{J(w,b)}}{\partial{b}} = \frac{1}{m} \sum_{i=1}^{m} (f(x^i)-y^i)$
其中$f(x^i) = wx^i+b$
对于线性回归损失,他的损失函数图像是一个凸函数,只有一个全局最小值,没有局部最小值
选择合适得到学习率,就可以得到$min(J(w,b))$
线性回归的梯度下降也是batch gradient descent,批次梯度下降每次更新关心整批的训练样例
多元线性回归
假设特征有$n$个,定义$\vec{x} = \begin{bmatrix} x_1 & x_2 & x_3 & … \end{bmatrix}$,参数$\vec{w} = \begin{bmatrix} w_1 & w_2 & w_3 & … \end{bmatrix}$
则$f_{\vec{w},b}=\vec{w} \cdot \vec{x} +b$
·为两个向量的点积(dot)。
$$
\vec{w} \cdot \vec{x} = w_1x_1+w_2x_2+….+w_n*x_n
$$
矢量化:利用计算机的并行硬件,代码简洁、运行速度快
1 | f = np.dot(w, x) + b |
多元线性回归的梯度下降
PS: 正规方程:某些机器学习库在后端求$w,b$的方法,只适用于线性回归,而且速度慢,不要求掌握
特征缩放
不同特征的估计值范围差异很大,梯度下降等高线图可能某些轴范围宽某些窄,梯度下降过程中可能波 动
加快梯度下降速度
避免特征的取值范围差异过大,将其进行缩放,几种常见方法:
- 除以最大值,$x_{1,scale} = \frac{x_1}{max}$, $x \in [0,1]$
- 均值归一化Mean Normalization
- 求均值$\mu$
- $x_1 = \frac{x_1-\mu}{max-min}$
Z-score归一化- 求标准差$\sigma$,均值$\mu$
- $x_1 = \frac{x_1-\mu}{\sigma}$
判断梯度下降是否收敛:
- 观察iteration-loss曲线是否平稳 2. 自动收敛测试,当loss小于一个很小的值时停止(难用)
选择合适学习率:从0.001开始,每次乘以3,对比$J(w,b)$与迭代次数的关系,选择合适的$\alpha$
特征工程
利用知识和直觉设计新特征,通常通过转化与组合,使模型做出更准确的预测
多项式回归:可以添加$x^q$项更好地拟合数据图像,$f(x)=w_1x^3+w_2x^2+w_1x^1+b$
此时特征缩放尤为重要
分类-逻辑回归
解决二分类问题
sigmoid函数
输出介于$(0,1)$
$g(z)= \frac{1}{1+e^{-z}},z \subseteq R$
logistic regression:
$f_{\vec{w},b}(\vec{x})=g(\vec{w} · \vec{x}+b) = \frac{1}{1+e^{-(\vec{w} · \vec{x}+b)}}$
输出值可以理解为分类为1的可能性
$f_{\vec{w},b}(\vec{x})=P(y=1|\vec{x};\vec{w},b)$
决策边界decision boundary
以0.5作为阈值,当$\vec{w} · \vec{x}+b \ge 0$,取值1;当$\vec{w} · \vec{x}+b <0$,取值0
$\vec{w} · \vec{x}+b = 0$称为决策边界
多项式回归也适用于非线性的决策边界
成本函数
如果使用平方误差成本函数,有多个局部最小值,$J(w,b)$不是凸函数,不适用于逻辑回归
定义
$$
J(w,b)=\frac{1}{m}\sum_{i-1}^{m}L(f_{w,b}(x^{(i)},y^{(i)})
$$
其中L代表单个样例的loss,J代表总的cost
$$
L(f_{w,b}(x^{(i)},y^{(i)})=-log(f_{w,b}(x^{(i)})) \quad if\quad y^{(i)}=1
$$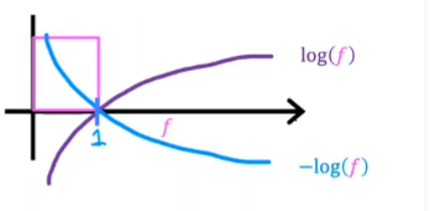
当y等于1,预测值越靠近1损失越小
$$
L(f_{w,b}(x^{(i)},y^{(i)})=-log(1-f_{w,b}(x^{(i)})) \quad if \quad y^{(i)}=0
$$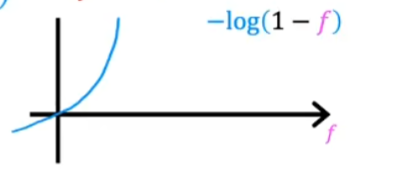
当y等于0,预测值越靠近0损失越小
简化成本函数
$$
L(f_{w,b}(x^{(i)},y^{(i)})=-y^{(i)} log(f_{w,b}(x^{(i)})) - (1-y^{(i)})log(1-f_{w,b}(x^{(i)}))
$$
得到
$$
J(w,b) = -\frac{1}{m} (y^{(i)} log(f_{w,b}(x^{(i)})) + (1-y^{(i)})log(1-f_{w,b}(x^{(i)})))
$$
成本函数是凸函数,便于实现梯度下降
梯度下降
对J求偏导
$\frac{\partial{J(w,b)}}{\partial{w}} = \frac{1}{m} \sum_{i=1}^{m} (f(x^i)-y^i)x^i$
$\frac{\partial{J(w,b)}}{\partial{b}} = \frac{1}{m} \sum_{i=1}^{m} (f(x^i)-y^i)$
其中$f(x^i) = \frac{1}{1+e^{-(\vec{w} · \vec{x}+b)}}$
可以使用相似方法进行特征缩放
过拟合问题
过拟合虽然可能完美通过训练集,但是有高方差,泛化能力差。应该避免欠拟合(高偏差high bias)和过拟合(高方差high variance)。
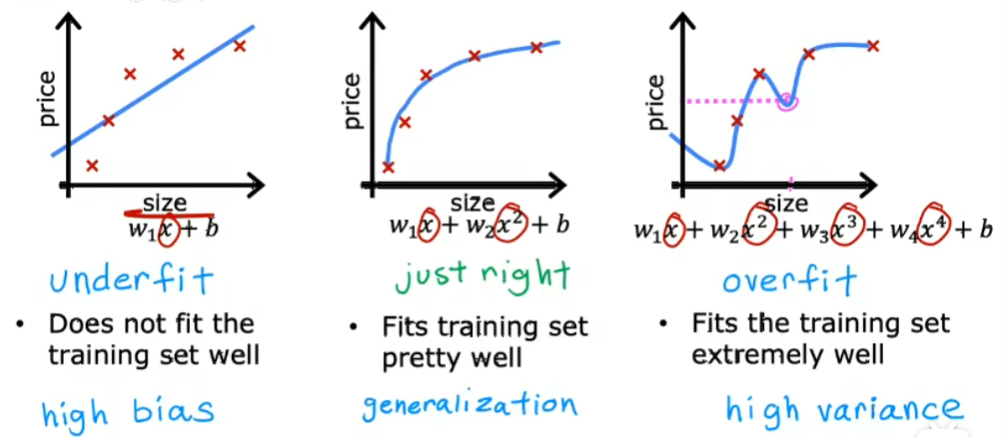
解决过拟合
- 收集更多训练数据
- 特征筛选,选择特征的一个子集
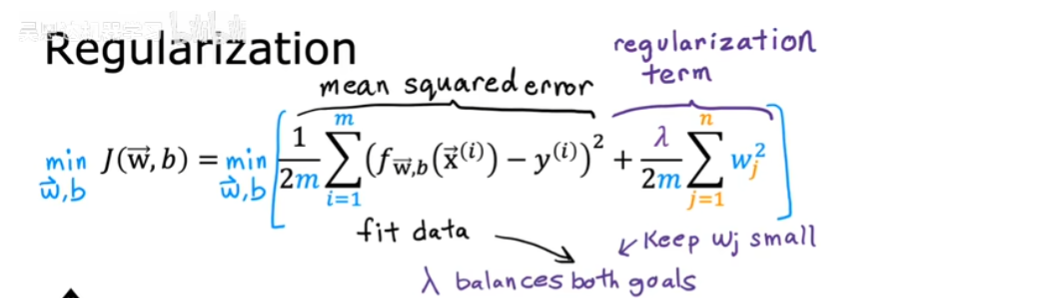
- 正则化(Regularization):在维持多项式回归的基础上,减小参数$w_j$的值,减小一些特征的影响
正则化
如果不知道哪个特征是重要的,一般惩罚所有特征,防止过拟合
$$
J(w,b) = \frac{1}{2m} \sum_{i=1}^{m} {(y^i-\hat{y})}^2 + \frac{\lambda}{\alpha m}\sum_{j=1}^{n} {w_j}^2
$$
其中$\lambda$为正则化参数,$\alpha$为学习率,缩放得
$$
J(w,b) = \frac{1}{2m} \sum_{i=1}^{m} {(y^i-\hat{y})}^2 + \frac{\lambda}{2 m}\sum_{j=1}^{n} {w_j}^2
$$
这样使得$w_j$尽可能小,几乎为0
参数$b$是否正则化无关紧要
需要选择合适的$\lambda$,太大趋于直线,太小惩罚效果不明显
- 正则化线性回归
对$J(w,b)$求偏导不断同步更新w,b的值
$$
\frac{\partial{J(w,b)}}{\partial{w}} = \frac{1}{m} \sum_{i=1}^{m} (f(x^i)-y^i)x^i+\frac{\lambda}{m}\sum_{j=1}^{m}{w_j}
$$
$$
w = w- \alpha (\frac{1}{m} \sum_{i=1}^{m} (f(x^i)-y^i)x^i+\frac{\lambda}{m}\sum_{j=1}^{m}{w_j}) = (1-\alpha \frac{\lambda}{m})w+…..
$$
- 正则化逻辑回归
$$
J(w,b) = -\frac{1}{m} (y^{(i)} log(f_{w,b}(x^{(i)})) + (1-y^{(i)})log(1-f_{w,b}(x^{(i)})))+ \frac{\lambda}{2 m}\sum_{j=1}^{n} {w_j}^2
$$
求导式和线性回归相同,只是需要注意正则化项偏导数没有求和
$f(x^i) = \frac{1}{1+e^{-(\vec{w} · \vec{x}+b)}}$
Course 2
神经网络
起源于设计算法来模拟人脑活动(但无需过于重视深度学习的生物动机),21世纪定义为深度学习
利用别人训练的神经网络参数称为推理或者预测
为了简化表达使用全连接,一层可以使用上一层的所有特征,对于不重要的特征可以选择适当的参数
神经网络不需要手动设计它可以学习的功能,在隐藏层自动提取特征(输入层->隐藏层->输出层)
多层神经网络叫做多层感知机
神经网络中的层
讨论层数通常是隐藏层和输出层,不包括输入层
每一层输入向量$\vec{x}$或$\vec{a}_{i-1}$,经过当前层中多个神经元的逻辑回归处理,输出新的向量$\vec{a}^{[l]}$,进入到下一层/输出结果
即$a_j^{[l]} = g(\vec{w}_j^{[l]} \cdot \vec{a}^{[l-1]} + b_j^{[l]})$
$j$表示神经元单元序号,$l$表示层数,$g(x)$为sigmod函数
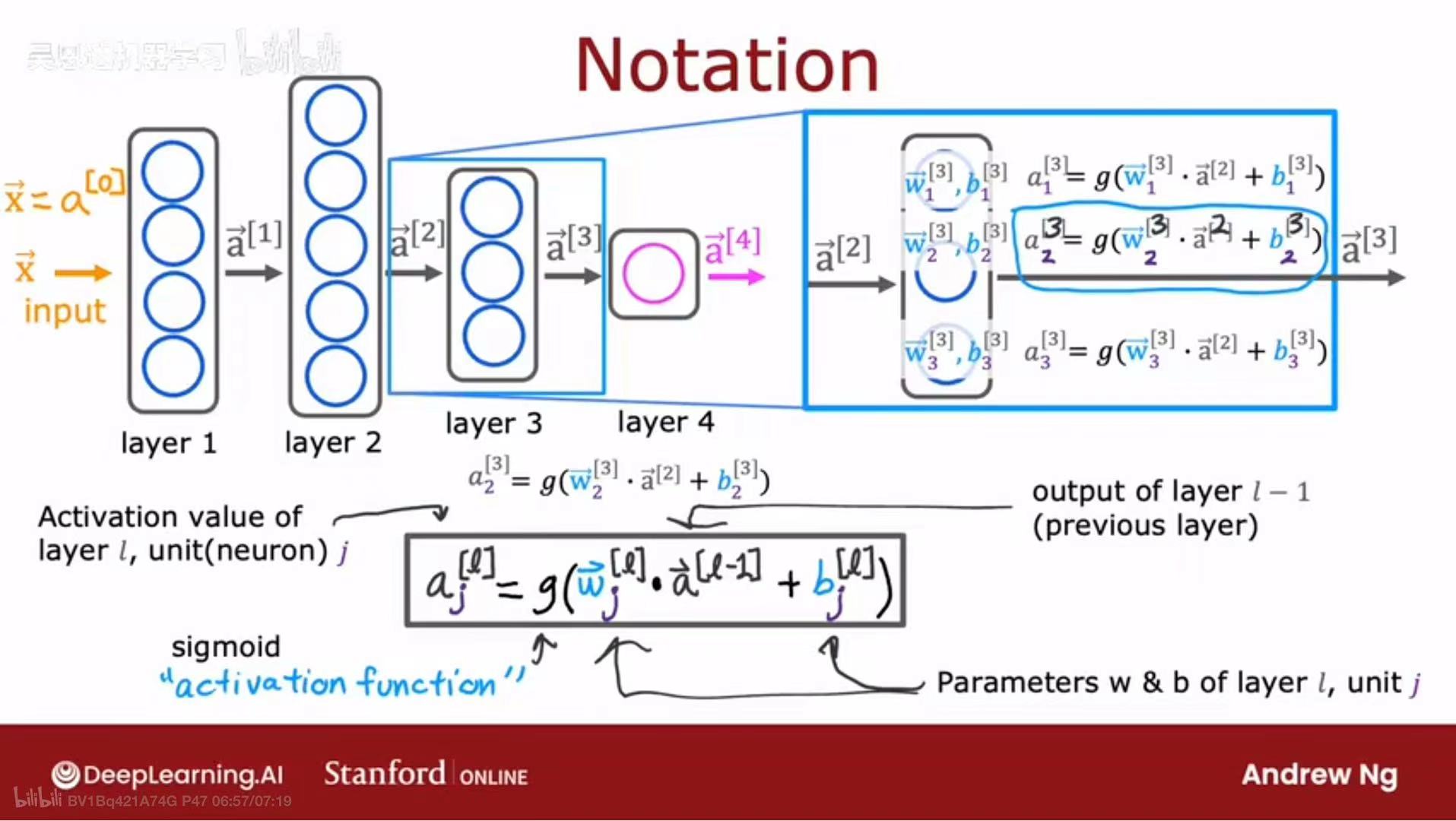
$a_j^{[l]}$构成$\vec{a}^{[l]}$

前向传播(forward prop)
从输入初步传递到输出,即为前向传播
一般实现
1 | def dense(a_in, W, b, g): |
使用框架(TensorFlow/Pytorch))进行矢量化加速
模型训练步骤
- 指定如何在给定输入X和参数的情况下计算输出(模型结构)
- 指定损失函数
- 训练模型以最小化损失函数
二元交叉熵损失
$$
L(f_{w,b}(x^{(i)},y^{(i)})=-y^{(i)} log(f_{w,b}(x^{(i)})) - (1-y^{(i)})log(1-f_{w,b}(x^{(i)}))
$$
通过反向传播计算偏导数
激活函数
用ReLU函数代替sigmoid激活,$g(z) = max(0,z)$
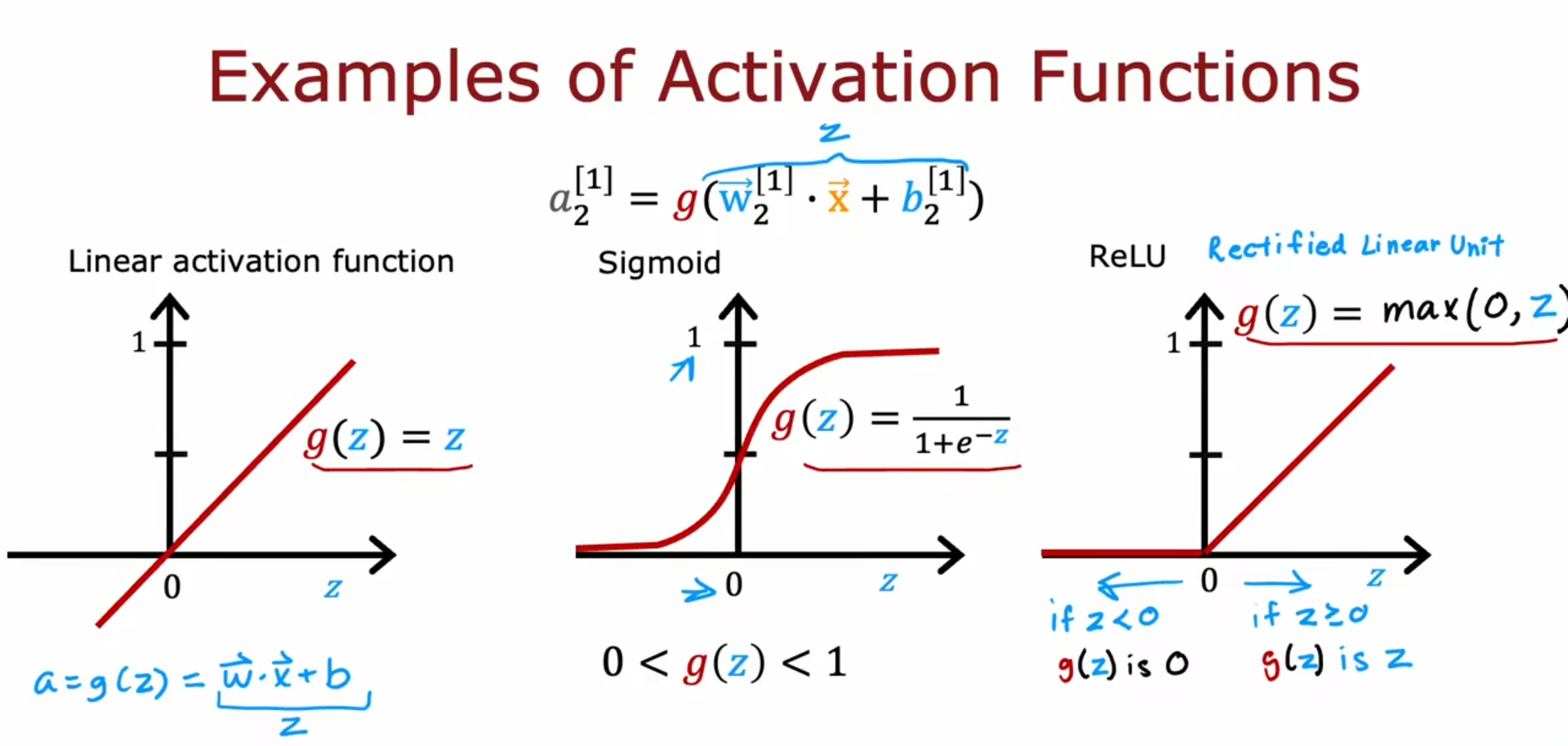
如何选择合适的激活函数?
取决于要预测的y,对于神经网络的输出层:
- 二分类——> sigmoid
- y可正可负的回归——> linear
- 回归中y大于等于0 ——> ReLU
对于神经网络的隐藏层建议使用ReLU
ReLU常用且更快
- 不涉及指数运算
- 当一个函数在许多地方都是平的,梯度下降会很慢,ReLU只有一端(x->-∞),而sigmoid两端都是
为什么需要激活函数?
对于隐藏层,只使用线性的所有层等价于线性回归
对于输出层,得到的结果显然可以仅仅使用线性回归(输出层用线性)或者逻辑回归(输出层用sigmoid)求解
多分类问题
softmax回归算法(logistic 推广)
$z_1=\vec{w_1}·\vec{x_1}+b_1$
$a_1=\frac{e^{z_1}}{e^{z_1}+…+e^{z_n}} = P(y=1|\vec{x})$
即,设有N个分类
$z_i=\vec{w_1}·\vec{x_i}+b_i$
$$
a_i = \frac{e^{z_i}}{\sum_{k=1}^{N} e^{z_i}}=P(y=i|\vec{x})
$$
其中$a_1+a_2+…+a_N=1$
softmax损失函数
回顾logistic回归
$$
L(f_{w,b}(x^{(i)},y^{(i)})=-y^{(i)} log(f_{w,b}(x^{(i)})) - (1-y^{(i)})log(1-f_{w,b}(x^{(i)}))
$$
二分类问题,设$a_1 = f_{w,b}(x^{(i)})$,即$y=1$的概率
则$a_2 = 1-f_{w,b}(x^{(i)})$,即$y=0$的概率
简化为
$loss = -log(a_1)$ 如果$y=1$
$loss = -log(a_2)$ 如果$y=0$
对于softmax回归算法
$$
loss(a_1,a_2,…,a_N,y) = \left{\begin{matrix} -log(a_1) \quad if \quad y=1\ -log(a_2) \quad if \quad y=2 \ … \ -log(a_N) \quad if \quad y=N \end{matrix}\right.
$$
神经网络中的softmax
输出层变为N个神经元
注意:之前的激活函数$g(z_1)$只是$z_1$的函数,但是softmax是$z_1 … z_n$的函数
softmax改进
$log$函数当x趋于0变化一些都会影响很大,所以尽量不舍入$a_i$,得到精确得到损失
不先计算出$a_i$,再带入损失函数
而是直接
$$
loss_i=-log(\frac{e^{z_i}}{e_{z_1}+…+e_{z_N}})
$$
此时输出层只需要linear即可(就是不计算$a_i$),同时开启from_logits=True
1 | model.compile(loss=SparseCategoricalCrossEntropy(from_logits=True)) #稀疏分类交叉熵损失 |
from_logits=True的作用
需要概率时再调用softmax
1 | logits = model(X) |
多标签分类

将每个标签看做一个二分类问题,输出层n个logistic函数,输出的y是一个向量。
高级优化方法
传统的梯度下降学习率固定
Adam(Adaptive Moment estimation)
如果看到学习率太小,而多次向同一个方向下降,会自动加大学习率
如果看到学习率太大,某个参数值来回振荡,会自动减小学习率
可以自动调整学习率$\alpha$
对于每个参数都有一个$\alpha$
选择optimizer=adam即可
其他的网络层
卷积层(Convolutional Layer)
每个神经元只能看到前一个层输入的一部分
- 加快计算速度
- 需要更少的数据,不容易过拟合
有多个卷积层,即卷积神经网络
每一层的单元只查看输入的一部分
构建机器学习系统
评估一个模型
特征只有一到二个还可以通过画图判断过拟合或者欠拟合,但是再多的特征就不适用了。
将数据集分为训练集和测试集(73或者82开)
分三步计算

注意计算error时不包括正则化项
过拟合$J_{train}$很低,$J_{test}$很高,很好地评估模型的泛化能力
对于分类问题,error就不再用交叉熵损失,直接用算法正确或者错误分类的个数(准确率accurate rate)
如何选择模型
数据集分为三个子集,训练集$J_{train}$,交叉验证集$J_{cv}$,测试集$J_{test}$
交叉验证集交叉检查不同模型的有效性和准确性,cross validation也叫dev set/validation set
$J_{train}$优化参数,$J_{cv}$选择模型,也叫优化超参数,$J_{test}$评估模型的泛化能力
数据样本不够时622开可以,但是数据样本够的时候后两者不宜太多。
偏差和方差
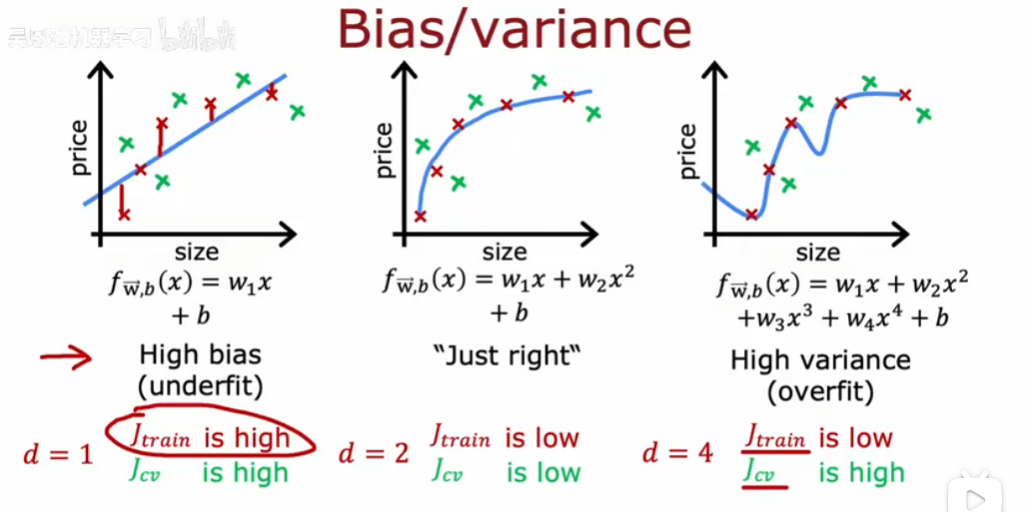
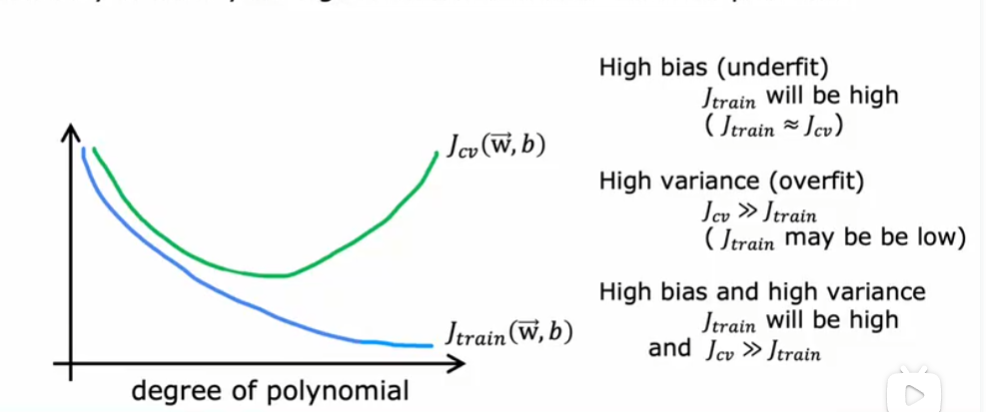
高偏差意味着在训练集上表现不好,高方差意味着在交叉验证集表现比训练集上差得多
高方差和高偏差同时存在是有可能的,大部分在神经网络中,线性回归不太可能。
正则化项参数对偏差和方差的影响:
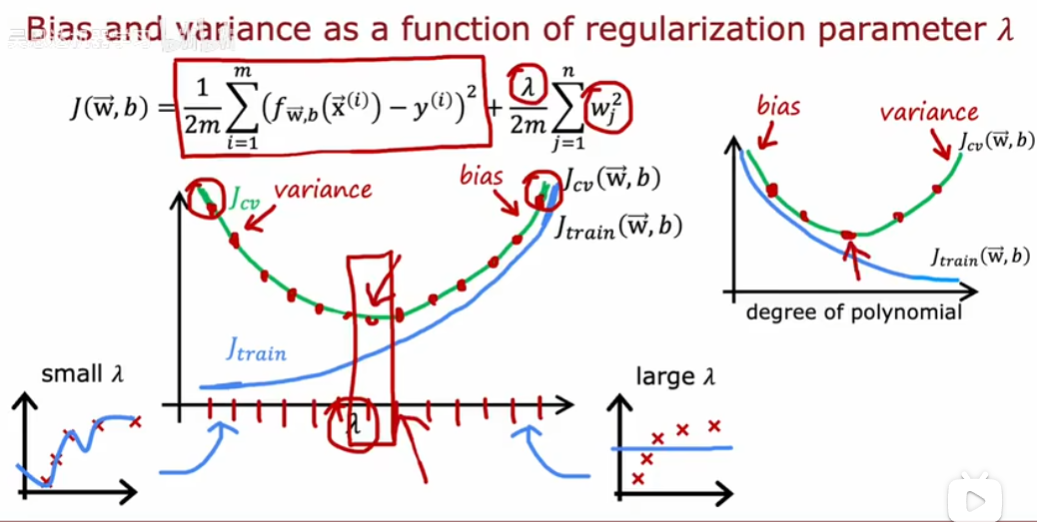
但是这些数值多少才算大/小呢?需要建立基准性能标准,通常是衡量人类在这项任务做的有多好。另一种估计性能基线水平的方法是,是否有一些前人实现的算法来建立性能的基线水平。通过自己的模型效果和基准的比较判断是否有高方差/高偏差的问题

学习曲线
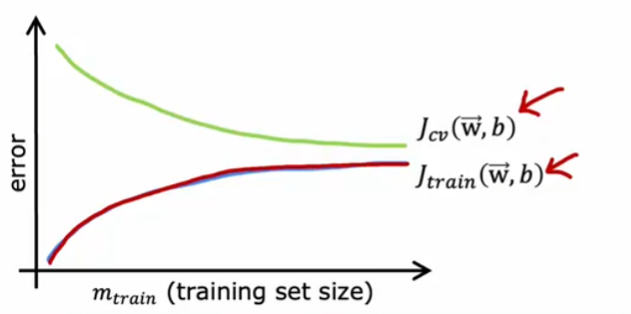
高偏差时

高方差时
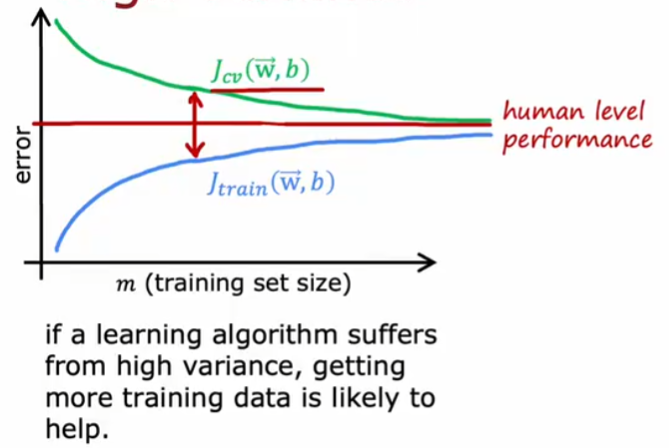

判断高方差或者高偏差决定下一步怎么做
神经网络中的偏差和方差
大型的神经网络有很小的偏差,所以只需要关注方差
并且在合适的正则化下,大型神经网络也会和更小的神经网络工作的一样好甚至更好
但是大型网络计算比较昂贵
1 | layer = Dense(unit=25, activation="relu", kernel_regularizer=L2(0.01)) |
开发机器学习系统的迭代
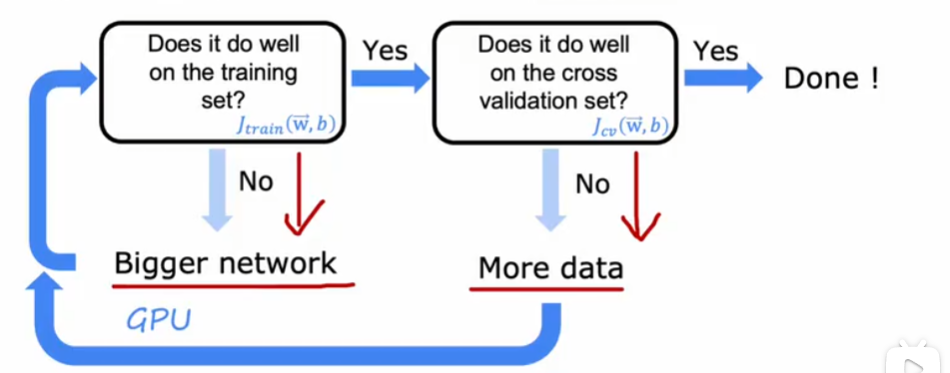
误差分析
在交叉验证集手动选出几个(几百个)分类错误的例子,计数,归类几个原因,找到比较多的错误分类类型,更新学习算法
添加数据
由误差分析,可以针对性地选择一些特定的数据,对于图像和语音识别,常用数据增强,用原有的数据样本创造新的样本
例如旋转,放大,缩小图片,更改图片对比度,扭曲图片,对输入的x施加失真或变换。对语音添加背景噪声等
此外还有数据合成,对于OCR文字识别,可以在真实图片基础上,更改字体,生成新的数据。一般在计算机视觉
AI = Code(algorithm/model) + Data
迁移学习(Transfer Learning)
对于神经网络,假设要进行0-9分类,但是数据集很小,可以借用有一个很大数据集的猫狗等1000类分类的神经网络,使用其中除了输出层以外的所有参数。
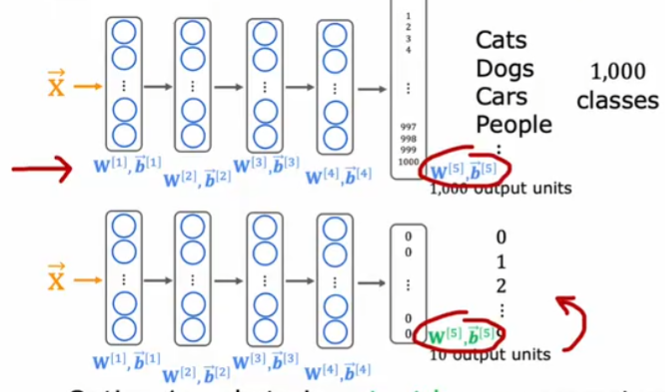
第一步叫做监督预训练(supervised pretraining),获得除了输出层以外的层的权重;第二步叫做微调(fine tuning),更改输出层的权重
这样就可以在一个只有很小数据集的训练中,通过别的有很大数据集的不太相关的任务中学习
通常下载别人预训练好并开源的神经网络,微调输出层参数来很好地学习自己的任务,但是输入x的类型(图片、音频、文本)也要和预训练模型一样

机器学习项目的完整周期
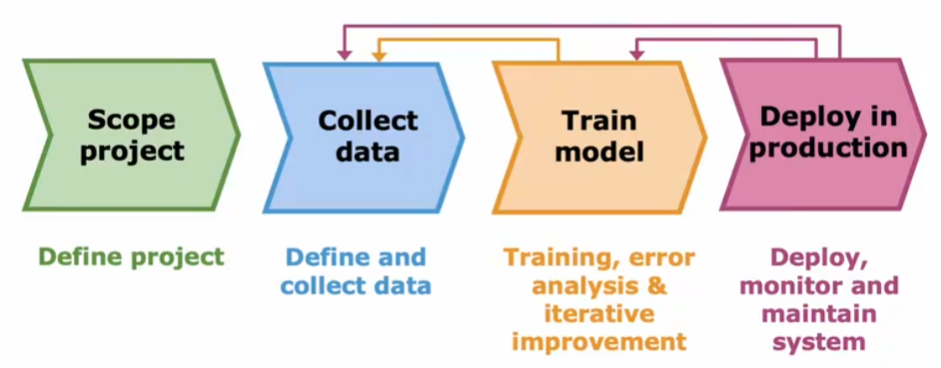
部署
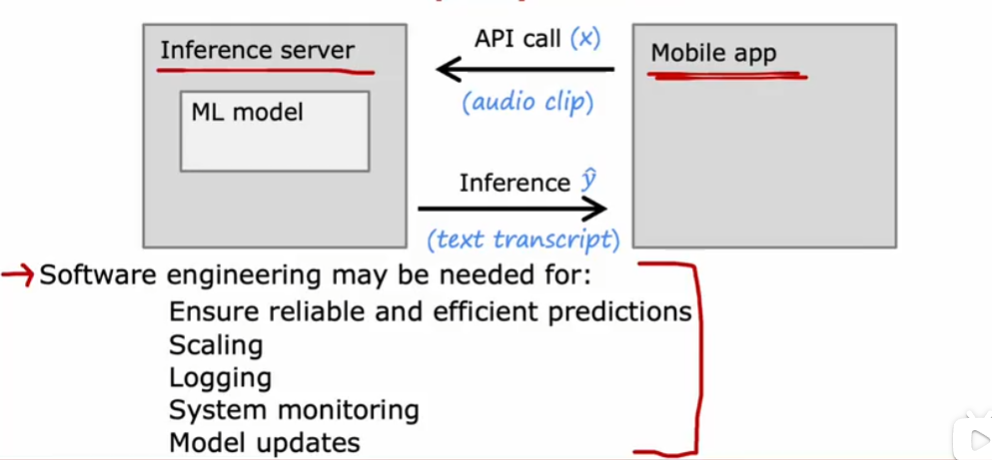
MLOps(Machine Learning operations):机器学习运维,系统构建,部署,维护机器学习系统的实践活动来确保机器学习系统可靠,监测损耗和及时更新。
关注公平、偏见、伦理
倾斜数据集的误差指标
某个系统的正例和负例不一定都是对半开,例如判断某个稀有的病,构造混淆矩阵,包括真正例,假正例,真负例,假负例
常用的计算指标是精确度(precision)和召回率(recall)
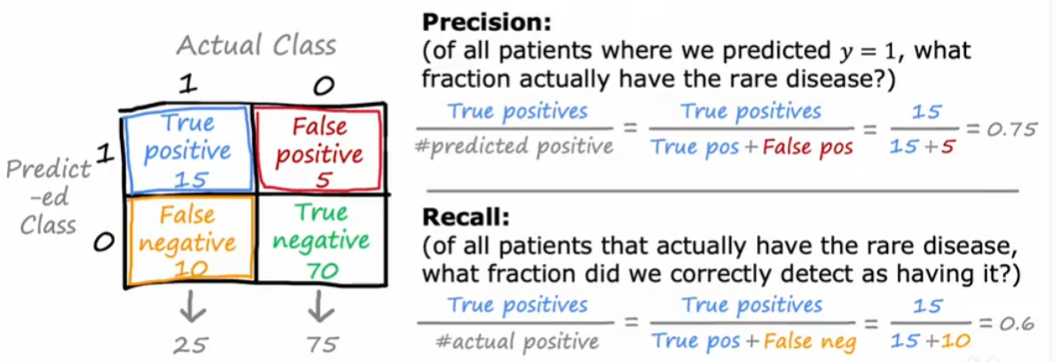
精确度展示预测出的的真实精确程度,召回率展示实际真实中预测出的精确程度
权衡:
当我们只有十分确信时才设置y=1,设置logistic门槛为大于0.5,会导致精确度提高,召回率降低
当我们不希望错过实际上的y=1,设置logistic门槛为小于0.5,导致精确度降低,召回率提高
通过设置threshold权衡precision和recall
F1 score:自动组合精确度和召回率,选择最佳值,强调有比较低的值的算法(可能效果不好)
$F1 score = \frac{1}{\frac{1}{2}(\frac{1}{P}+\frac{1}{R})} = 2\frac{PR}{P+R}$
决策树
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
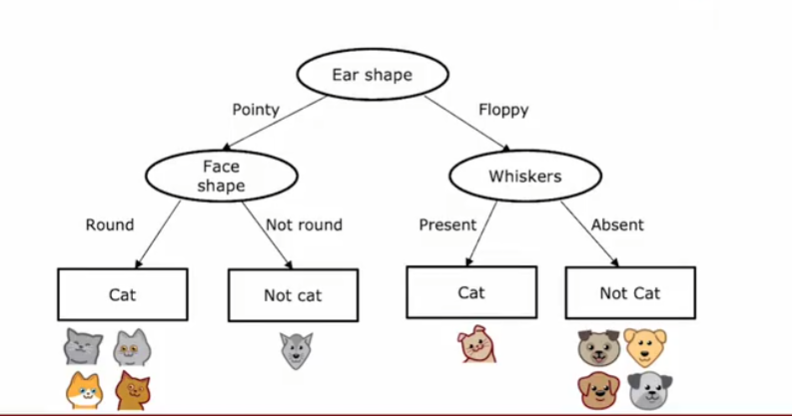
决策树学习:
- 如果选择每个节点选择什么特征来分类?
应该最大化纯度,每一边的种类尽可能少
- 什么时候停止分类?
当一个节点100%是一个种类
当分裂节点时会导致树超过最大高度(超参数)
当提高的纯度分数低于一个门槛值
当一个节点的样本数量低于一个门槛值
衡量纯度(purity)
熵是对一组数据杂质的度量,$p_1$是目标种类数量在总数量得到占比,$p_0 = 1 - p_1$
$H(p_1)=-p_1log_2(p_1)-p_0log_2(p_0) = -p_1log_2(p_1)-(1-p_1)log_2(1-p_1)$
注意:$0log(0) = 0$
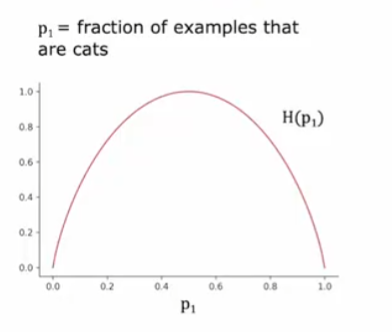
减小熵:信息增益(Information Gain)
当选择一个节点选择什么特征时,计算左右分支的熵,并进行加权平均计算,选择有最小结果的特征
实际上是测量熵的减小量,由根节点原来的熵值$H(p)$减去左右分支的加权平均熵,此时选择更大的值
为什么?当熵减小的量很小时,可以选择不分裂,而避免过拟合

更一般地

p是当前节点样本中正例的个数,w是从上一节点样本中选择的样本数(当前样本/上一节点样本)
总结
在根节点以所有数据样本开始
计算所有特征的信息增益,选择最大的
对选择的特征分裂,创建左右分支
保持分裂直到遇到终止条件:
- 当一个节点100%是一个类
- 当分裂节点会导致树超过最大高度
- 信息增益的值小于某个门槛值
- 节点的样本数量小于某个门槛值
实际上是一个递归的过程
独热编码(One Hot Encoding)
实现有两个以上离散值的特征:如果一个类的特征有k个离散值,创建k个二元特征(0/1)
这样又转变为原来的左右分支分裂的情况
连续值特征
选定一个阈值,判断数据样本大于或者小于该阈值
分割点将训练样本排序后取每对的中间值,10个样本就有9个分割点
对分割点分别计算信息增强来选择阈值
回归树
分裂时,改成尽量选取输出的方差(Variance)小的特征
w还是从上一节点样本中选择的样本数(当前样本/上一节点样本),之后计算加权平均方差
再用上一个节点所有数据的方差减去加权平均方差,选取最大的
分类的结果是样本的平均值
使用多个决策树
单一决策树对数据中的微小变化十分敏感,所以要建立多个决策树(Tree Ensemble),并进行投票,使得算法更加健壮
放回抽样
从n个样本中放回地抽取n次,结果作为一个新的数据集
随机森林(Random Forest)
给定一个训练样本数m,进行b次的训练(一般不超过100),每次放回抽样创建一个新的大小为m的数据集,在此基础上训练一个决策树
b个决策树构成袋状决策树(Bagged Decision Tree),输出结果进行投票决定最终输出
对于每个节点,当要选择一个特征来分裂的时候,如果有n个特征可用,随机选择一个$k < n$大小子集,使得算法只从这个子集里的特征选择信息增益最高得到特征进行分裂,当n很大时,经验做法是取$k = \sqrt{n}$
XGBoost(eXtreme Gradient Boosting)
极端梯度提升树,与前面不同的是,进行放回抽样的时候,不是让每个样本有$\frac{1}{m}$的概率被抽中,而是更可能抽到前面训练的树错误匹配的样本
思想:关注我们已经训练好的树做的不好的地方,在之后刻意地尝试优化这部分
- 提升树的开源实现
- 快速,有效
- 很好的设定结束分裂的标准
- 内置正则化
什么时候使用决策树
一个或多个决策树
- 在表格化和结构化的数据上工作的很好
- 不建议在非结构化的数据上,例如图片,音频,文本
- 训练快速
- 决策树是人类可以理解的(可解释性)
神经网络
对于所有类型的数据都能工作的很好
比决策树更慢
可以很好地使用迁移学习(预训练+微调)
当建立一个有多个模型一起工作的系统,链接神经网络会更简单(输出都是光滑的,连在一起仍然可微,决策树一次只能训练一个)
Course 3
除了监督学习,机器学习还包括
- 无监督学习
- 聚类
- 异常检测
- 推荐系统
- 强化学习
聚类
一堆数据点中自动查找相互关联或者相似的数据点
K-means
首先随机初始化K个簇中心点$\mu_1 ,\mu_2… \mu_k$,$\mu$应该是一个向量,与输入有相同的维度
- 将每个点分配给离他最近的中心点(centroid质心)
- 将中心点移动到分配的点的平均中心
- 重复前两步,直到中心点不再移动,K-means算法收敛
1 | Repeat{ |
损失函数

$c^{(i)}$是$x^{(i)}$被分配到的簇的下标(1-k)
$u_k$是簇k
$\mu _{c^{(i)}}$是$x^{(i)}$被分配到的簇
损失函数就是每个点到其分配到的簇的距离平方的平均值,其中距离是欧几里得距离
也叫Distortion Function
初始化
选择$K<m$
随机选择K个训练样本,将$\mu_1 ,\mu_2… \mu_k$设定为这几个点,每次运行容易得到局部最小值,所以运行多次,找到效果最好的点
1 | for i = 1 to 100{ |
选择簇的个数
肘法(Elbow Method)
选取不同的K,绘制损失函数曲线,选择肘点,但是这个方法不通用,不是每一次都有肘点
所以K的选择还是按照之后的任务目的选择
异常检测
密度估计(Density estimation)
根据数据集建立模型$p(x)$,其中特征向量x的概率,对于$x_{test}$,求得$p$,若$p(x_{test})<\epsilon$,认为出现了异常(anomaly)
高斯分布
Gaussian Distribution,也叫正态分布(Normal Distribution)
$p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{-(x-\mu)}{2\sigma^2}^2}$
其中$\mu$是平均值,$\sigma$是标准差
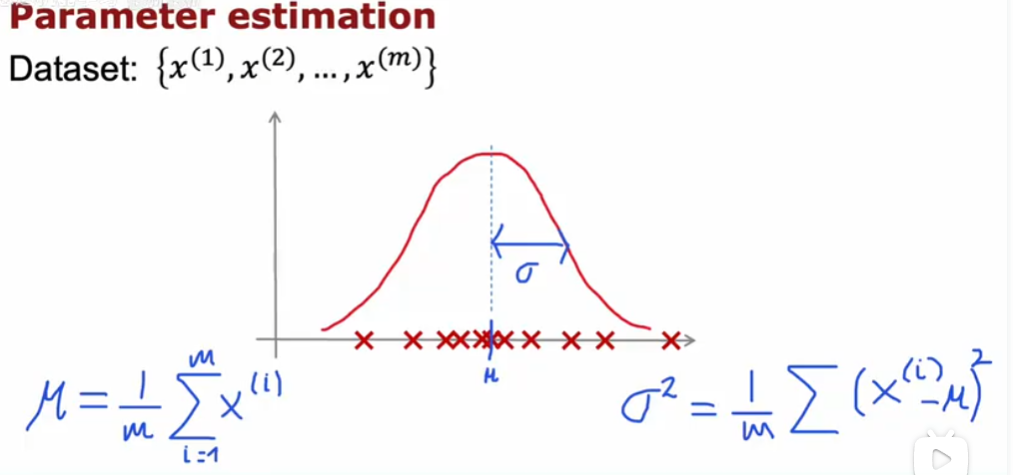
算法实现
对于有多个特征的输入$\vec{x}$,$\vec{x} = [x_1, x_2 … x_n]$
$$
p(\vec{x}) = p(x_1;\mu_1,\sigma_1^2) * p(x_2;\mu_2,\sigma_2^2) … p(x_n;\mu_n,\sigma_n^2) = \prod_{j=1}^np(x_j;\mu_j,\sigma_j^2)
$$
开发和评估异常检测系统
通常在训练集训练(无标签),在cv集加入异常的样本,打上标签0/1,选择合适的$\epsilon$使得在cv集可以很好地工作,对于异常样本很多的情况下,可以再使用测试集
流程:
在训练集$x_1…x_m$上拟合模型$p(x)$
在交叉验证集或者测试集上,预测y(如果小于epsilon为1否则为0)
之后计算真正例,精确度Precision,召回率Recall和F1分数等指标衡量模型,并且选择更好的参数$\epsilon$
权衡异常检测和监督学习
异常检测:有很多种异常,对于算法来说很难从已知的异常中学习,因为未来的异常可能与当前的完全不一样
监督学习:有足够的正例使得算法学会识别正例,未来的正例也是与当前训练集里的类似
特征选择
监督学习中,特征如果不重要可以让参数变得小一点,但在异常检测中,特征的选择更加重要
- 绘制直方图,转换保证特征符合高斯分布,注意cv集和测试集也要同样转换(开根号,取对数)
- 检查是否在cv集效果不好,分析原因,看看有没有新的特征可以选取
推荐系统
$r(i,j) = 1$表示用户j为电影i打分
$y^{(i,j)}$表示用户j为电影i打的分
$w^{(j)}, b^{(j)}$是用户j的参数
$x^{(i)}$是电影i的特征向量
对于用户j和电影i,预测评分$w^{(j)} \cdot x^{(i)}+b^{(j)}$
$m^{(j)}$表示用户j打分的电影数量
通过训练学习$w^{(j)}, b^{(j)}$
$$
\min_{w^{(j)}b^{(j)}}J\left(w^{(j)},b^{(j)}\right)=\frac{1}{2m^{(j)}}\sum_{(i:r(i,j)=1}\left(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)}\right)^{2}+\frac{\lambda}{2m^{(j)}}\sum_{k=1}^{n}\left(w_{k}^{(j)}\right)^{2}
$$
对所有用户都要学习参数$w^{(1)},b^{(1)},w^{(2)},b^{(2)},…,w^{(n_u)},b^{(n_u)}$
$$
\left.\mathrm{J}\left(
\begin{array}
{cc}{w^{(1)},} & {…,w^{(n_{u})}} \
{b^{(1)},} & {…,b^{(n_{u})}}
\end{array}\right.\right)=\frac{1}{2}\sum_{j=1}^{n_{u}}\sum_{i:r(i,j)=1}\left(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)}\right)^{2}\quad+\frac{\lambda}{2}\sum_{j=1}^{n_{u}}\sum_{k=1}^{n}\left(w_{k}^{(j)}\right)^{2}
$$
协同过滤算法
在上面的例子中,我们已经得到了每部电影的特征的值是多少,可以使用线性回归,但是当不知道的时候,需要使用$w^{(j)}, b^{(j)}$来推测每部电影的特征值是多少
$$
\mathrm{J}(x^{(i)})=\frac{1}{2}\sum_{j:r(i,j)=1}\left(w^{(j)}\cdot x^{(i)}+b^{(j)}-{y^{(i,j)}}\right)^{2}+\frac{\lambda}{2}\sum_{k=1}^{n}\left(x_{k}^{(i)}\right)^{2}
$$
学习得到$x^{(1)},x^{(2)},…,x^{(n_m)}$
$$
\mathrm{J}\left(x^{(1)},x^{(2)},…,x^{(n_{m})}\right)=\frac{1}{2}\sum_{i=1}^{n_{m}}\sum_{j:r(i,j)=1}\left(w^{(j)}\cdot x^{(i)}+b^{(j)}-y^{(i,j)}\right)^{2}+\frac{\lambda}{2}\sum_{i=1}^{n_{m}}\sum_{k=1}^{n}\left(x_{k}^{(i)}\right)^{2}
$$
将这里与上面提到求w,b的算法结合起来,构成协同过滤算法:
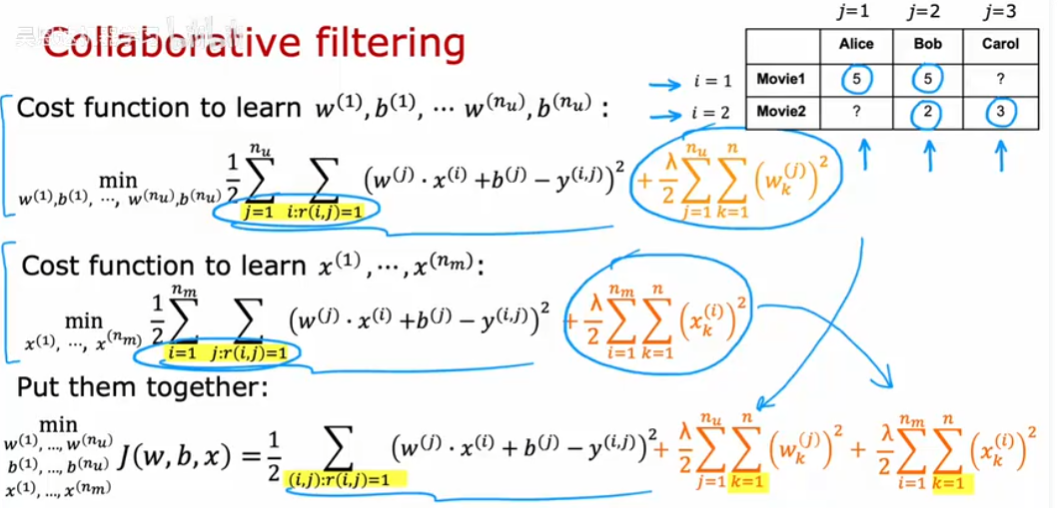
梯度下降时,w,b,x都是参数

二进制标签
1-用户看到物品之后参与点击,停留,添加喜欢,购买
0-用户看到物品之后忽略
?-用户没有看到物品
预测$y^{(i,j)}=1$的概率,由$g(w^{(j)} \cdot x^{(i)}+ b^{(i)})$,g是logistic函数
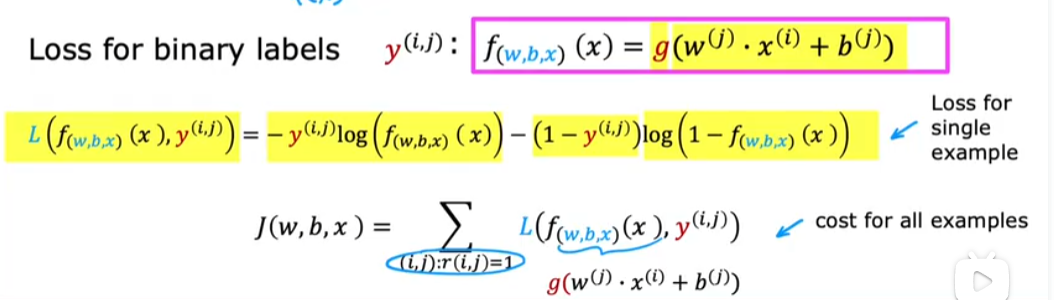
均值归一化
Mean Normalization
- 求均值$\mu$
- $x_1 = \frac{x_1-\mu}{max-min}$
求出每个电影的平均用户平方$\mu_i$,构建向量$u$
对于用户j,预测其在电影i的评分:
$w^{(j)} \cdot x^{(i)}+ b^{(i)} + \mu_i$
以至于不会当用户没有评分时认为评分接近0,而是接近平均值
查找相关项目
对于项目$i$的特征$x^{(i)}$,为了找到相关的项目$k$,需要找到$x^{(k)}$与$x^{(i)}$相似
选取小的$\sum_{l=1}^n(x_l^{(k)} - x_l^{(i)})^2$
也可以写作$||x^{(k)} - x^{(i)}||^2$
协同过滤算法的限制
冷启动问题
- 如何对没有什么用户打分的项目评分?
- 如何对没有对很多项目打分的用户推荐一些项目?
没有很多信息的时候利用辅助信息
基于内容的过滤算法
协同过滤:基于用户的评分与你的评分的相似推荐项目
基于内容过滤:基于用户和项目特征的匹配良好程度推荐项目
但是电影的特征数和用户的特征数大概率不一样多,所以需要提取出$v^{(j)}$和$v^{(i)}$(相同维度)进行匹配
对于v的获取,使用神经网络
可以分别建立user network和movie network,使用相同维度的输出层,将结果进行点积
也可以将两个网络合并,在内部进行点积输出结果
$$
J=\sum_{(i,j):r(i,j)=1}\left(v_{u}^{(j)}\cdot v_{m}^{(i)}-y^{(i,j)}\right)^{2}+\text{NN regularization term}
$$
为了找到电影i的相似电影,找$||v^{(k)} - v^{(i)}||^2$小的电影,最为相似
Retrieval and Ranking
通常样本有几百万或者几千几万,不可能对每个样本构造神经网络,所以采用检索和排名
检索:生成可能得项目列表,比如从用户最近观看的10个电影中找到相似的,从最常看的3个类别中选出其中的top10,用户所在国家的top20。将检索的项目列表,去除重复项目和用户已经观看
排名:对这些检索出的有限个项目进行学习,根据结果进行排名
权衡检索的项目数量
强化学习
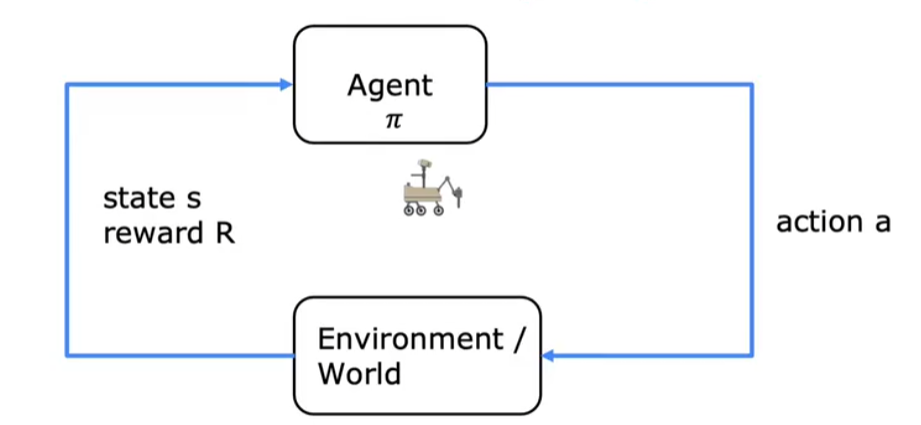
强化学习(Reinforcement Learning,简称RL)是一种机器学习范式,它通过让智能体(Agent)与环境(Environment)进行交互,学习如何做出最优决策,以最大化累积奖励(Reward)。强化学习的核心思想是通过试错(Trial and Error)的方式,让智能体逐步探索环境,找到最优的行为策略。
涉及状态,行动,奖励,折扣系数,回报,策略
回报
指的是系统获得的奖励总和
折扣系数$\gamma$,是一个无限接近1的数字,例如0.9,0.99
$\text{Return} = R_1 + \gamma R_2 + \gamma^2R_3+…$,直到终止状态
策略
状态state通过策略π实行行动a
$\pi(s) = a$,指明状态s情况下需要进行的决策a,从而最大化回报
马尔科夫决策过程
Markov Decision Process(MDP)
状态-动作价值函数
State-action value function,也叫Q-function,Q*,Optimal Q function
$Q(s,a)$的值等于你从状态s开始执行一个动作a之后,表现的最好所获得的回报
在状态s的最好回报就是$max_aQ(s,a)$
在状态s的最好动作的就能够提供$max_aQ(s,a)$的
Bellman方程
$s$:当前状态
$a$:当前状态的决策
$R(s)$:当前状态的奖励
$s’$:采取动作a后的状态
$a’$:在状态s’采取的动作
$Q(s,a) = R(s)+\gamma max_{a’}Q(s’,a’)$
R(s)也叫即时奖励,表示你可以立刻得到的奖励
后一项是从状态s’表现得最好获得的回报
$\text{Return} = R_1 + \gamma R_2 + \gamma^2R_3+… = R_1 + \gamma[R_2 + \gamma R_3+…]$
随机环境
由于不可控因素,强化学习问题是随机的,不一定会按照某个序列,而是有很多个可能得序列,得到不同的奖励
所以问题不是最大化回报,而是最大化奖励之和得到平均值,也就是期望
$\text{Return} = \text{Average}(R_1 + \gamma R_2 + \gamma^2R_3+…) = \text{E}(R_1 + \gamma R_2 + \gamma^2R_3+…)$
Bellman Equation变成:
$Q(s,a) = R(s)+\gamma \text{E} [max_{a’}Q(s’,a’)]$
连续状态空间
状态参数可能是连续的,比如坐标,角度,速度
同时状态可能有多个,比如xyz坐标,速度等
此时也叫连续状态马尔科夫决策过程
学习状态值函数
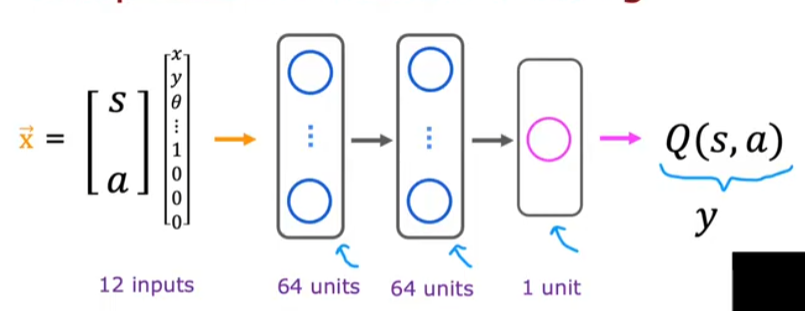
以随机猜测$Q(s,a)$初始化神经网络
重复:
采取措施,得到$(s,a,R(s),s’)$元组
存储最近的10k个 $(s,a,R(s),s’)$元组(Replay Buffer)
训练网络:
创建10k个训练集,其中$x=(s,a)$,$y = R(s)+\gamma max_{a’}Q(s’,a’)$
训练$Q_{new}$使得$Q_{new}(s,a) \approx y$
令$Q=Q_{new}$
虽然刚开始Q是随机猜测的,但是随着训练迭代,Q的值会变成真实值的良好估计
改进
- 神经网络架构
可以直接将输出层改成每种决策的结果输出,就不用分别计算多次不同决策,只用计算一次就行
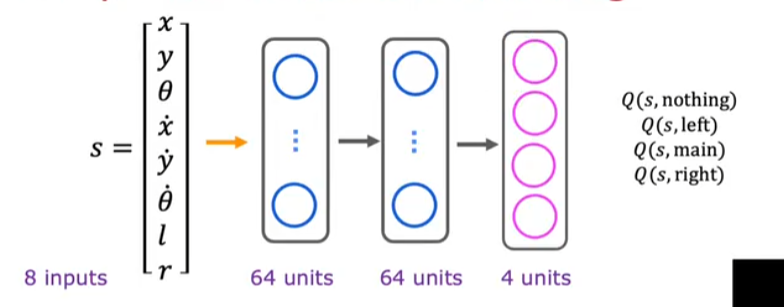
- $\epsilon$贪心策略
当正在学习时如何选择决策,不应该都选择能最大化Q的a,因为当Q时随机初始化的,大的不一定好。
应该选择大概率例如0.95选择最大化的Q,也是贪心greedy,或者exploitation。再0.05概率随机选择别的策略(探索exploration)
小概率的值就是epsilon,这个策略也叫做epsilon贪心策略,开始的e比较大,逐渐减小。
- 小批量$mini-batch$
将数据集分成几个小的集合,每次迭代查看一个小数据集,梯度下降最开始虽然不是朝最优方向,但是越来越优
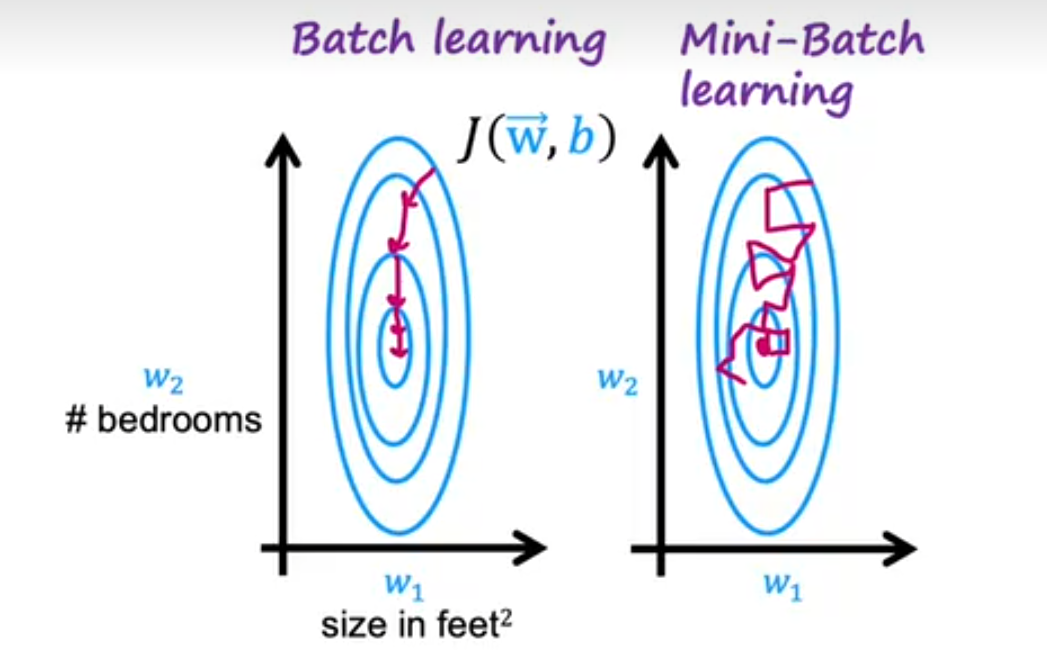
假设子集大小为1000;
具体过程,是先取出1000个数据,前向计算出结果,再反向传导计算出代价函数对w和b的偏导数;接着计算出代价函数的和,然后取这1000次的平均值,进行优化;然后再拿出1000个数据,再次计算代价函数与导数,再次优化,重复进行直到全部数据集取完即可。
在强化学习中,可以把10k的数据集分解训练多个模型
- 软更新
令$Q=Q_{new}$时,不直接把$w,b$换成$w_{new},b_{new}$
而是
$$
w = 0.01w_{new} + 0.99w
$$
$$
b = 0.01b_{new} + 0.99b
$$
对参数进行微小调整
